How we added sleep when idle feature to NeetoDeploy and reduced cost

January 19, 2024
We are building NeetoDeploy, a compelling Heroku alternative. Stay updated by following NeetoDeploy on Twitter and reading our blog.
What is sleep when idle feature
"Sleep when idle" is a feature of NeetoDeploy, which puts the deployed application to sleep when there is no hit to the server for 5 minutes. This helps reduce the cost of the server.
"Sleep when idle" feature can be enabled not only for the pull request review applications, but for staging and production applications too. Many folks build applications to learn and for hobby. In such cases, there is no point in running the server when the server is not likely to get any traffic. Since NeetoDeploy billing is based on the usage "Sleep when idle" feature helps keep the bill low for the users.
Let's say you build something and you deployed to production. You shared it with your friends. For a day or two you got a bit of traffic, and after that you moved on to other things. If "sleep when idle" is enabled then you don't need to worry about anything. If the server is not getting any traffic then you will not be billed.
How is Neeto using sleep when idle feature
At neeto, we are building 20+ applications at the same time. It means lots of pull requests for all these products and thus lots of PR review apps are created.
For a long time, we were using Heroku to build the review apps. However when NeetoDeploy started to become stable, we movedto generating PR review apps from Heroku to NeetoDeploy. This helped reduce cost.
How to make deployments sleep when idle?
This video describes how "sleep when idle" feature is implemented.
Keeping the apps running only when they're being used involves two steps:
- Scaling the deployments down and bringing them back up again
- Figuring out when to do the scaling
The deployments can be scaled easily using the kubectl scale command. For
example, if we want to turn our deployment off, we can run the following to
update our deployment to zero replicas, essentially destroying all the pods.
kubectl scale deployment/nginx --replicas=0
We can also delete our service, ingress or any other resource we might have created for our deployment. The configuration of the deployment itself would still be present in the cluster even when we make it sleep, since the Kubernetes Deployment is not deleted.
When we want to bring our app back up again, we can use the same command to spin up new pods:
kubectl scale deployment/nginx --replicas=1
The challenge was to figure out when to do this. We decided that we'd have a threshold based on the time the app is last accessed by users. If the application is not accessed for more than five minutes, we consider the application to be idle and we will scale it down. It'll be brought back up when a user tries to access it again.
Exploring existing solutions
There are existing CNCF projects like Knative and
Keda, which can potentially be used to achieve what we want
here. We spent some time exploring these but realized that these solutions
weren't exactly suitable for our requirements. Kubernetes also natively has a
HPAScaleToZero
feature gate
which enables the
Horizontal Pod Autoscaler
to scale down deployments to zero pods, but this is still in alpha and, hence is
not available in EKS yet.
Ultimately, we decided to write our own service for achieving this. The entire backend of NeetoDeploy was designed as a collection of microservices from day one. So it made sense to build our pod idling service as another microservice that runs in our cluster.
Figuring out when to make applications sleep
To know when applications can be idled, we need to know when people are accessing the applications from their browsers. Since all the requests to applications deployed on NeetoDeploy would go through our load balancer, it would contain the information of when every app was last accessed.
We use Traefik as our load balancer and we used Traefik's middlewares to retrieve and process the information of when apps are being accessed. We wrote a custom middleware to send all the request information to the pod idling service, whenever an app is being accessed. The pod idling service would store all the URLs, along with the timestamp at which they were accessed, in a Redis cache. The following graphic shows how the request information would be collected and stored by the pod idling service into its Redis cache, both of which are running within the cluster.
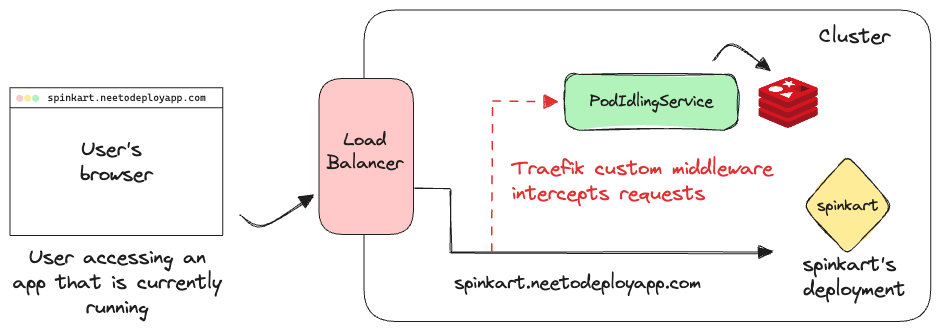
The pod idling service would then filter the apps that were last accessed more than five minutes ago. It then sends a request to the cluster to scale all these apps down. We'd also delete any related resources like the Services and the IngressRoutes used to configure networking for the deployments.
We first tested this by running the service manually, and sure enough, all the inactive deployments are filtered and scaled properly. We then added this as a cron job in the pod idling service, which would run every five minutes. This means that no app would run for more than five minutes if they're not being used.
But wait! How would we bring the app back up after scaling it down?
Building the downtime service
As we discussed above, we use Traefik's IngressRoutes to route traffic to the
application being accessed. We made use of the
priority parameter
of IngressRoutes to boot up apps that are sleeping. Essentially, we created a
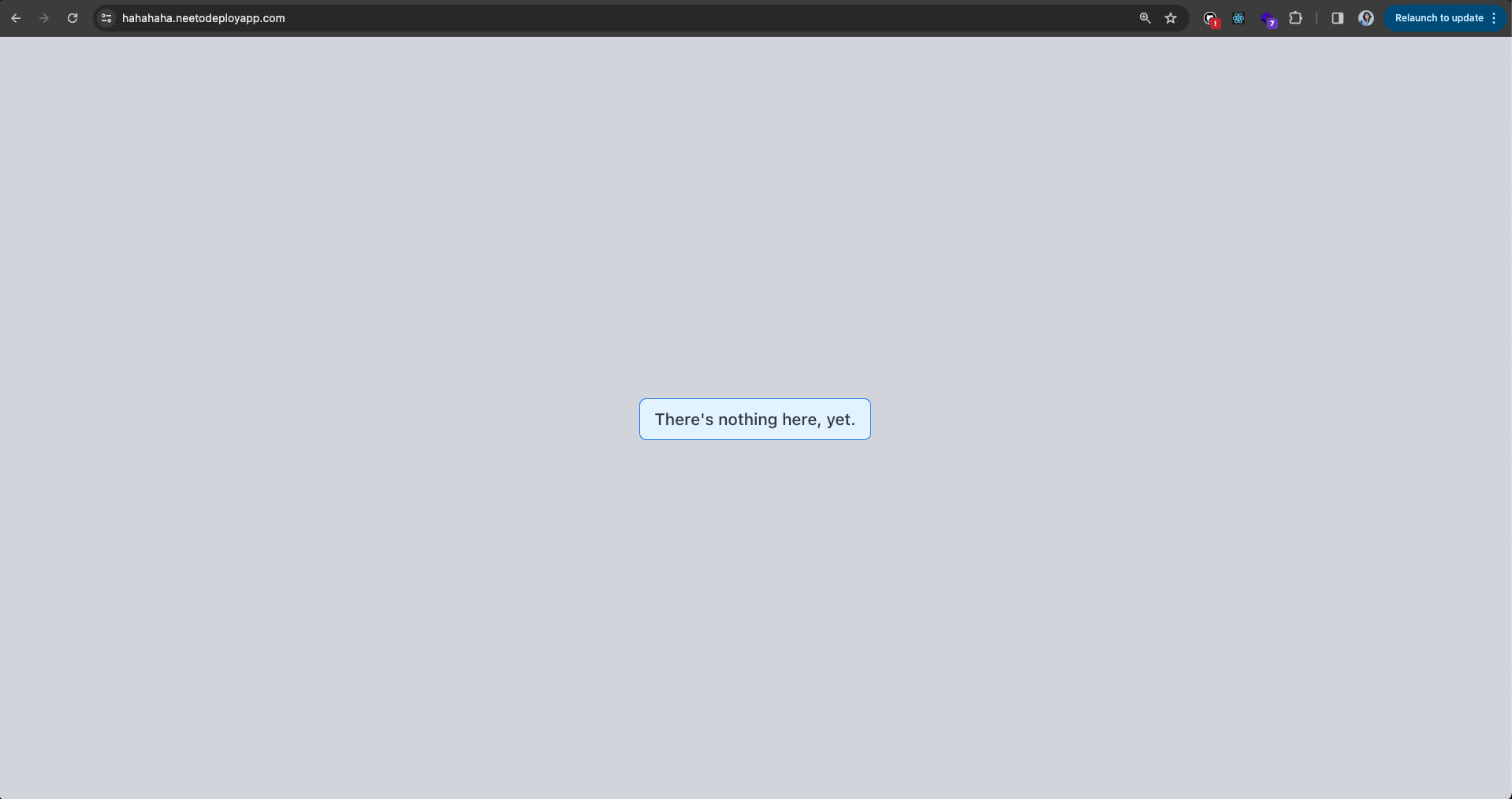
wildcard Traefik IngressRoute that points to a "downtime service" deployment,
which is a React app that serves a message of There's nothing here, yet to let
users know that the app they're trying to access doesn't exist. You can see this
in action if you visit a random URL in NeetoDeploy, say something like
nonexistent-appname.neetodeployapp.com
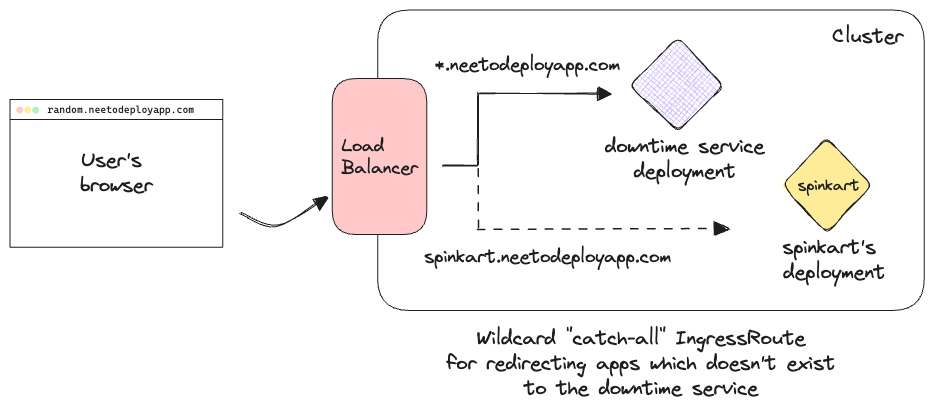
Wildcard IngressRoutes have the least priority by default. So if we create a "catch-all" wildcard IngressRoute, any invalid url without an IngressRoute of its own, can be redirected to a single Service in Kubernetes. This is how we're redirecting non-existent apps to the page shown above. In the following graphic, we can see how a request to a random URL is routed to the downtime service with the wildcard IngressRoute.
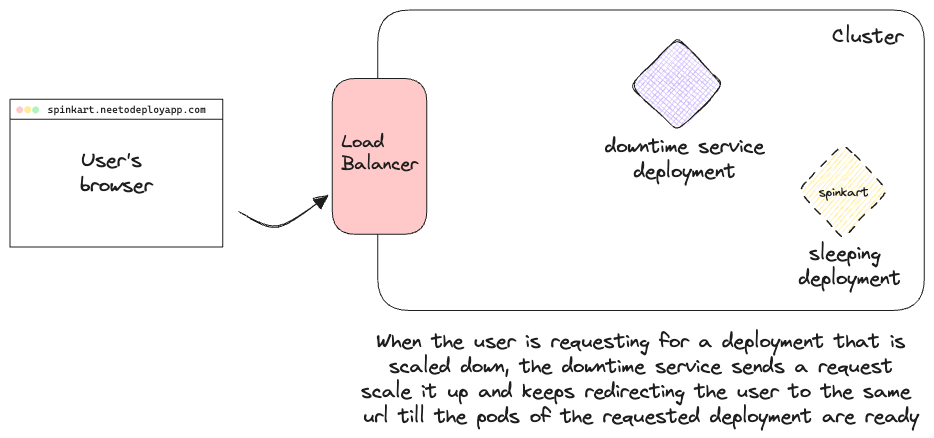
This also means that if an app is scaled down by the pod idling service and gets its IngressRoute deleted, the next time a user tries to access the app, the request would instead be routed to the downtime service. We need to handle the scale up logic from the downtime service.
Whenever a user requests a URL that doesn't have an IngressRoute, there are two possibilities.
- The app doesn't exist.
- The app exists, but is currently scaled down.
The downtime service would first check the cluster if the requested app is present in the cluster in a sleeping state. If not then the user will be served the "There's nothing here, yet" page. If there is a sleeping deployment, however, we boot it back up. The downtime service sends the scale up request to the cluster. We keep redirecting the user back to the url till the app is up and running. This redirection would keep happening until the app is scaled up since we create the Service and IngressRoute only after the pods of the app are running. At this point, the request will be routed to the correct pod by the app's IngressRoute, since it has a higher priority than the wildcard IngressRoute of the downtime service. All of these steps are illustrated in the GIF below:
This design worked flawlessly and we were able to bring back scaled down applications with as low as 20-30 seconds of wait time.
Conclusion
We've been running this setup for almost a year now, and it has been working smoothly so far. Pod idling service and the downtime service started as simpler microservices and continue to evolve, adapting to the increasing demand as we grow.
If your application runs on Heroku, you can deploy it on NeetoDeploy without any change. If you want to give NeetoDeploy a try, then please send us an email at [email protected].
If you have questions about NeetoDeploy or want to see the journey, follow NeetoDeploy on X. You can also join our community Slack to chat with us about any Neeto product.
Follow @bigbinary on X. Check out our full blog archive.